Learning from Data is a Machine Learning MOOC taught by Caltech Professor Yaser Abu-Mostafa. I took the course in 2014 through edX. It was a great course, well-organized and into the details.
Recently I have been reviewing the notes and the summary of the course, and I thought I might just post them here. All my code used for the homework can be found at https://github.com/Chaoping/Learning-From-Data.
Lecture 2: Is Learning Feasible?
Lecture 2 starts with a question of probability: Can a sample tell anything about the population? In probability, the answer is yes – and we know the bigger the sample, the better it represents the population. Now instead of confidence interval, here we use another way to measure the sample size – precision trade off, that is, the Hoeffding’s inequality: $$!\mathbb{P}[|\mu – \nu |>\epsilon] \le 2e^{-2\epsilon^2N}$$
(Read more at: http://www.jdl.ac.cn/user/lyqing/statlearning/09_22_Inequalities.pdf)
With Hoeffding’s Inequality, we can say that “$$\mu = \nu$$” is “P.A.C” true (probably, approximately, correct). “Probably” because the probability of violation is small, and “approximately” because $$\epsilon$$ is small (with good size of $$N$$).
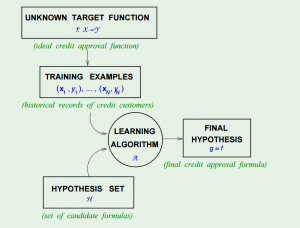
Now, consider a learning problem, the only assumption is that, the data we have, is simply a sample, generated with a probability distribution. The analogy is that, we know how a hypothesis performs on the training set, and with Hoeffding’s Inequality we believe it should reflect how the hypothesis will work on the data we haven’t seen. By changing the notation of $$\mu$$ and $$\nu$$, we have $$!\mathbb{P}[|E_\mathrm{in}(h) – E_\mathrm{out}(h) |>\epsilon] \le 2e^{-2\epsilon^2N}$$
However there is yet another problem – Hoeffding’s Inequality applies to each one of the hypothesis, but when we combine many hypotheses all together, it fails. It is because we “tried too hard”.
To solve it, we can give it a union bound. Since the final hypothesis $$g$$ is one element in the hypothesis set $$H$$, without giving any extra assumptions, we can safely say that $$!\mathbb{P}[|E_\mathrm{in}(g) – E_\mathrm{out}(g) |>\epsilon] \le 2Me^{-2\epsilon^2N}$$
Now with $$M$$ being the number of hypotheses in $$H$$, we once again give it a bound.